How AI Audio Description Works: Scene Detection, Script Writing, and Voiceover in One Pipeline
For decades, audio description was entirely a human craft — a describer watched a film, wrote a script in the dialogue gaps, then a voice actor recorded it in a studio. High quality, but slow and expensive: typically €500–€1,500 per finished hour, delivered in weeks.
AI has changed the economics and the timeline. But how does it actually work? This article breaks down the technology behind AI-powered audio description — from raw video ingestion to the finished mixed audio track.
What Is Audio Description?
Audio description (AD) is a narrated audio track layered over a film or video that describes visual information not conveyed by the existing dialogue or audio: character actions, scene changes, on-screen text, facial expressions, and plot-relevant visual details. It enables blind and low-vision viewers to follow a visual medium independently.
AD is mandated by WCAG 2.1 (Success Criterion 1.2.5), the European Accessibility Act (2025), the Americans with Disabilities Act, and broadcast regulations in the UK (Ofcom), US (FCC), and across the EU.
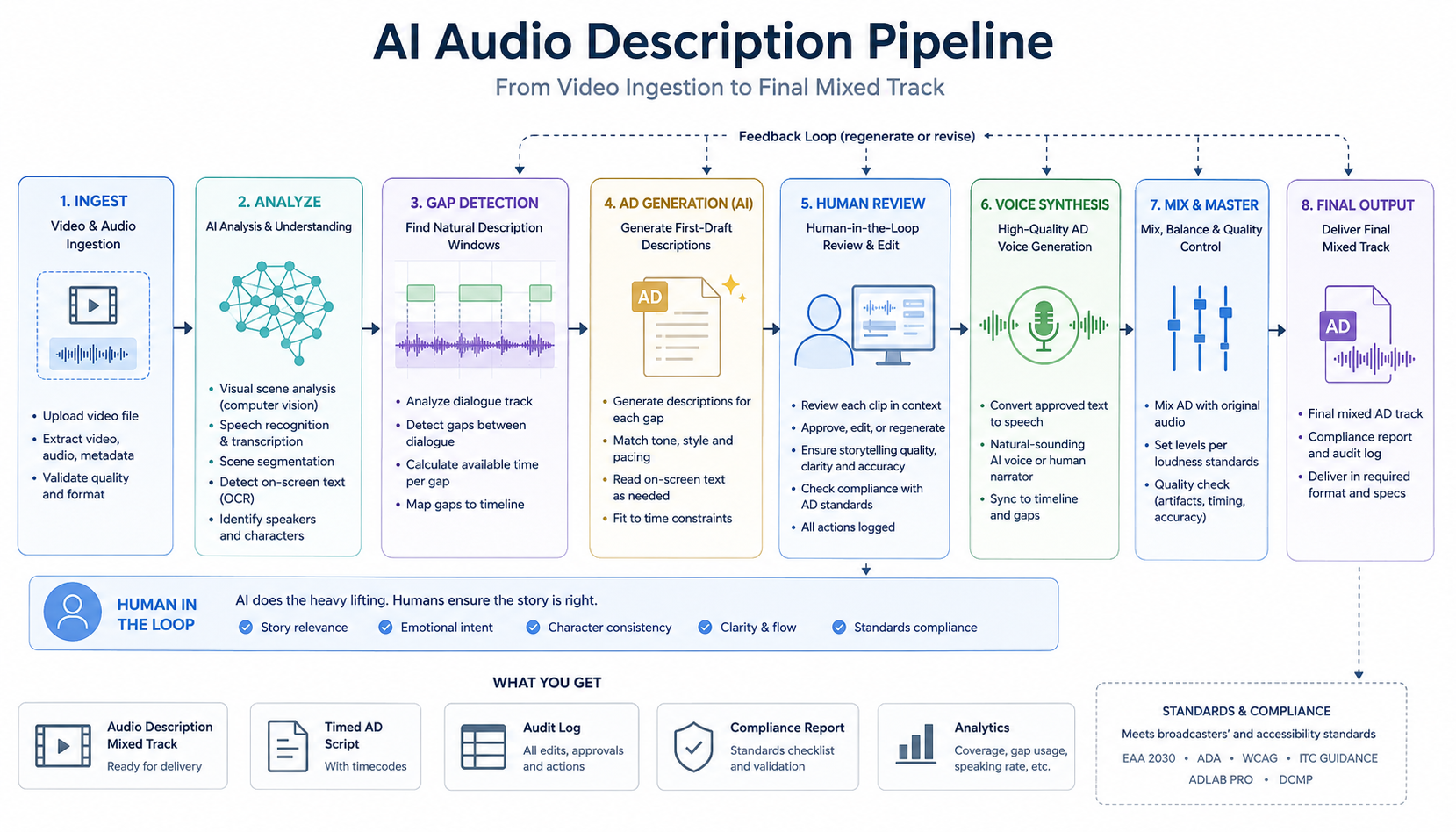
The Five Stages of an AI Audio Description Pipeline
Stage 1: Video Ingestion and Scene Segmentation
The pipeline begins when a video file (typically a ProRes, H.264, or H.265 master) is ingested. The first task is scene detection — identifying every cut, transition, and scene boundary.
Modern scene detection uses a combination of:
- Optical flow analysis to detect motion discontinuities at cuts
- Histogram differencing to catch fade-to-black and dissolve transitions
- Neural shot boundary detection models (e.g. TransNetV2) that achieve >95% F1 on standard benchmarks
The output is a timeline of shots with start/end timestamps — the structural skeleton the rest of the pipeline hangs on.
Stage 2: Dialogue Track Transcription and Gap Detection
The AD script must fit into the natural pauses between dialogue — inserting description while characters are speaking destroys intelligibility. This requires precise transcription of the existing audio.
Whisper-class ASR models (or faster distilled variants) transcribe the dialogue with word-level timestamps, enabling the pipeline to compute every gap in the speech track. Gaps are then classified by duration:
- < 1.5 seconds: Too short for AD insertion — skip
- 1.5–4 seconds: Short insertion — one brief sentence
- > 4 seconds: Full insertion — detailed description possible
The gap map becomes the AD script’s timing constraint.
Stage 3: Visual Understanding — What’s Happening on Screen?
This is the hardest part of the pipeline and the biggest differentiator between AI systems. The model must answer: What is visually significant in this clip, and would a blind viewer miss it without description?
This requires multimodal vision-language models (VLMs) such as GPT-4o Vision, Gemini 1.5 Pro, or fine-tuned open-source alternatives. Key inputs:
- Representative frame samples from each shot
- Scene context (what was described in previous shots)